JavaScript 编程艺术的读书笔记(一)
这几天复习审计复习的头昏眼花,间隙间把《javaScript DOM 编程艺术》一书看了一遍。嗯,做一做读书笔记,以后可以看看。
DOM
DOM(document object model)是文档对象模型。当宿主是浏览器,或者是需要解析标记性文本文档的时候,就会有DOM的概念。嗯,根据惯例,先讲理论。
文档 Document
文档简单的说,是字符串的集合,是标记符号的集合。对于一般的字符串而言,浏览器并不会对他们进行过多的解析,只有当这些字符串被能被浏览器识别的标记符号包裹的时候,浏览器才会对该文档进行对象化操作,生成DOM tree。
对象 Object
对象的话,DOM的本身之意其实就是把标记文档进行对象化,是他们能够成为可操作的对象节点。JavaSript的对象分成三类:
用户定义的对象
1
var a = {}; var o = new Object();
内建对象 js语言自带的对象,其实吧,我觉得每一个引用类型都是一个自建对象啊
array,function,RegExp,Date等除了那五个初始类型(Null,Undefined,Boolean,Number,String)
1 | var date = new Date(); var a = []; var a = new Audio(); var a = new String(); //tips:new String 得到是一个Object而不是string。 “asdfe” === new String("asdfe");//false |
- 宿主对象:
- window Object 窗口对象模型(BOM)是最基础的宿主对象
- document Obcject
- location
- history
- window Object 窗口对象模型(BOM)是最基础的宿主对象
模型 Model
模型的话,这个我的理解是解释的对象解析的本身关系的样子。嗯,DOM的话其实就是树啦,正所谓DOM tree嘛。用来表示各个对象节点之间的关系是什么。
一个简单的DOM tree如下图: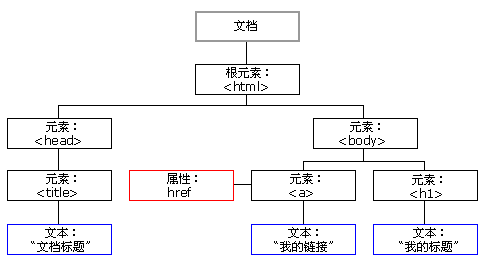
节点
嗯,如上图所示,每一颗文本树都有很多的节点。每一个节点都可以看作是一个可操作的对象。在DOM中,对象分为三类:
- 元素节点 (element node)就是每一个标签
- 文本节点 (text node) 元素节点中的文本对象
- 属性节点 (attribute node) 元素节点中的属性对象
对于下面这段html1
<p id="content">this is a <em>p</em> tag</p>
他的节点树是这样的:
嗯其中的id是属性节点。
DOM 的分级
最后说一下DOM的分级,DOM分成四级
- DOM 0
- DOM 1
- DOM 2
- DOM 3
等级从0到3,DOM的可操作性原来越强,具体的内容可以看这个。里面没有level 0的原因是因为它已经过时了。。。DOM 的level 2添加了对试图,样式,事件,节点操作的支持。
js的基本操作
嗯,DOM的基本的理论就在上面了,因为是小白,所以很多到东西并不是很清楚,希望大家多多指正啊~!下面说一下js的相关接口。
先记录一下DOM 0 级的一些操作接口,虽然很多都已经废弃了。
DOM 0 的操作接口
方法
一些老旧的方法:1
document.open() ; //打开document的操作流
document.write() ; //写入
document.writeln(); //写入并换行
document.close(); //关闭
上面所列的方法其实都已经不怎么用了。。。缅怀一下,当年我的第一个hello world。
属性
1 | document.bgColor //<body>的bgcolor属性(已不再使用) document.cookie //设置或返回与当前文档有关的所有cookie。 document.domain //关于同源策略安全限制,返回当前文档的域名。 document.lastModified //一个字符串,包含文档的修改日期。 document.location //和location是一样的 document.referrer //http refer document.title //返回当前文档的标题。 document.URL //等价于location.href //以下都是数组 document.anchors // 文档中锚的集合。 document.applets// 文档中小应用程序的集合。 document.forms//文档中表单的集合。 document.images// 文档中图片的集合。 document.links//文档中链接的集合 |
获取节点
嗯,现在回来讲如何从DOM tree中获取一个可以操作的节点。
原生实现
最简单的方法是以下几个只针对html:1
document.getElementById("id");
document.getElementsByTagName("p");//这里获得是一个数组
document.getElementsByName("name");
document.getElementsByClassName("class");
document.queryselector(".selector"); //得到最后一个匹配的对象
document.queryselectorAll("#all");//得到所有匹配的数组
嗯,其实这些选择器是支持连用的。1
document.getElementById("id").getElementByTagName("li");//获取id为id的标签下的所有li标签。
前三个是支持广泛的方法,后面的是ECMAS5之后提供的方法。我们可以用前三者来模拟后三者的实现:1
//最简单的
document.getElementByClass = function(n) {
var el = [],
_el = document.getElementsByTagName('*');
for (var i=0; i<_el.length; i++ ) {
if (_el[i].className == n ) {
el[el.length] = _el[i];
}
}
return el;
}
//优化一下
function getElementsByClassName(node,classname) {
if (node.getElementsByClassName) { //判断原生是否支持
return node.getElementsByClassName(classname);
} else {
return (function getElementsByClass(searchClass,node) {
if ( node == null )
node = document;
var classElements = [],
els = node.getElementsByTagName("*"),//获取所有的节点
elsLen = els.length,
pattern = new RegExp("(^|\\s)"+searchClass+"(\\s|$)"), i, j;//使用正则匹配,实现当多个class时候的取用。
for (i = 0, j = 0; i < elsLen; i++) {
if ( pattern.test(els[i].className) ) {//如果匹配成功放入新的数组
classElements[j] = els[i];
j++;
}
}
return classElements;//返回数组
})(classname, node);
}
}
//嗯,再给出一种更巧妙的方法
function getElementsByClassName(node,classname){
if(node.getElementsByClassName) return node.getElementsByClassName(classname);
else{
var res = [],
elems = node.getElementsByTagName("*");
for(var i = 0 ; i< elems.length; i++){
if (elems[i].indexof(classname) != -1){
res[res.length] = elems[i];
}
}
return res;
}
}
如果对这个感兴趣的话,还可以参考这位大神的实现。
剩下两个的话,其实就有点类似sizzle的选择器实现了。嗯,就不多说什么了。嗯,这里多说一点的是,优雅降级。
优雅降级
对于一些不兼容javascript的浏览器,通常情况下,我们要判断一下是否支持js。1
if(document.getElementById){
//do something
}
如果多个选择器判断则会出现嵌套,就像这样:1
if(document.getElementById){
if(document.getElementsByTagName){
if(document.getElementsByName){
//do something
}
}
}
额,这样就出现了我们所痛恨的金字塔形的代码,并不友好,我们友好一点1
function(){
if(!document.getElementById) return false;
//do something
}
如果有很多的话,其实可以这么写1
var d = document,
isDom = d.getElementById&&d.getElementsByTagName&&d.getElementsByName;
if(!isDom) return false;
这里有一个小问题,如果多人协作,我怎么才能保证,这种对浏览器支持的判断只做一次?我的想法如下:
嗯,可以定义一个全局变量,用来存放判断结果,这样,每次使用的时候,对那个全局变量进行一次校验就行了。
如果大家有更好的想法,请告诉我~!
设置和获取属性
获取属性
这个其实很简单的啦。1
document.getElementById("id").getAttrubute('attr');
设置属性
1 | document.getElementById("id").setAttrubute('attr'); |
这里要注意一点,只有对元素节点采用如上的方法哦。
嗯,今天就先这么多吧,明天再来。
